
今年 11 月,OpenAI、Google 與 Anthropic 先後釋出最新一代 AI 模型 GPT-5.1、Gemini 3 與 Claude Opus 4.5,使 AI 幻覺問題再度成為外界檢視的焦點。
在 2024 年底,輝達(NVIDIA)執行長黃仁勳曾表示 AI 幻覺短期內難以完全消除,
如今 2026 年, AI 幻覺依然是當前棘手的核心問題。
因此,我們需要的不只是能回答的 AI,而是能理解、能判斷、並能自我驗證的 AI。
換句話說,使用 AI 前的真正關鍵能力,不是提問,而是降低幻覺的能力。
本篇文章將帶你從基礎概念到實務技巧,掌握如何透過:
- 清晰提示詞
- 明確上下文
- 要求來源
- 拆解問題
- 鼓勵誠實
- 查核機制
來有效降低 AI 幻覺,讓你能更安心、更高效地把 AI 變成真正的工作夥伴。
AI 幻覺是什麼?3 大主要成因一次看懂

AI 幻覺(AI Hallucination)是指大型語言模型LLM(如 ChatGPT、Gemini)生成看起來合理但實際錯誤或虛構的資訊。
關鍵點在於:
- LLM 的核心工作是:預測下一個「最可能」出現的詞
- 它是根據訓練資料中的統計模式來「續寫」,而不是在「查真實資料」
- 無法真正理解真實世界,只是擅長模仿語言風格與結構
所以在以下三種情況常發生 AI 幻覺:
- 訓練資料本身有錯、過時或有偏見
- 某個主題在資料中資訊不足(冷門、太新)
- 題目太模糊或太複雜
而 AI 的幻覺來源主要包括:
1. 模型與訓練本身的限制
- 越早期、越小的模型(例如 GPT-3.5 以前),因為參數少、訓練資料有限,
對語言模式的掌握不夠精準,所以幻覺通常比較嚴重 - 新一代大型模型(GPT-4o、Gemini 1.5、Claude 3 等)雖然大幅降低了幻覺比例,
但仍不可能 AI 幻覺完全消失 - 若訓練資料本身有錯、過時或帶有偏見,模型就會把這些錯誤「學進去」,在回答時一併重現
2. Prompt 指令的品質
當指令設計不良時,AI 會被迫猜測使用者要什麼:
- 指令越模糊 → 模型越容易亂補資訊
- 要求一次完成很多步驟的推理 → 容易在中途出錯
- 問題內容又大又散(例如:同時問市場分析+技術細節+財報解讀) →
模型會拼命湊答案,幻覺機率自然升高
3. 對話持續太久造成「偏誤放大」
對話不是「一題一題獨立」,模型會被前文持續影響:
- 早期的錯誤資訊,後面回答會當成「事實」繼續引用
- 不相干的小聊、玩笑,有時也會混進正式回答裡
- 對話越長,模型越容易順著舊脈絡走偏,回答離原始問題越來越遠
8 個實用方法:幫你有效降低 AI 幻覺
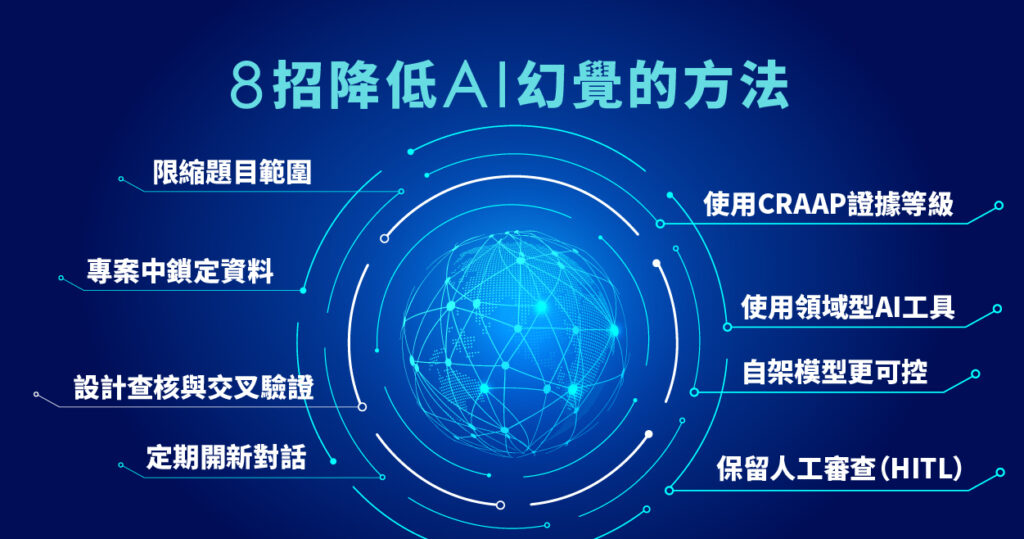
1. 降低複雜度、限縮範圍
題目越窄、越具體,AI 通常越準。
避免一次問一大串、又廣又散的問題,
2. 在專案內「鎖定資料範圍」
使用 GPT、NotebookLLM、RAG 或 Vector DB 時,可以這樣做:
- 先把專案相關資料餵給模型
- 之後的提問都在這個專案裡進行
好處是:
- 幻覺大幅下降
- 回答風格與資訊一致性高
但要注意:
同一個專案裡不要混聊不相關主題,避免資料被「污染」。
3. 在提示詞中設計「查核點」與「交叉驗證」
除了問答案,也要請 AI「檢查自己的答案」。
指令示例:
- 請在回答前自我檢查資料來源是否充足,如資料不足請明確指出。
- 請進行交叉驗證並列出不確定的部分。
4. 用「證據等級」框住回答品質(CRAAP 機制)
可以要求 AI 依照以下標準評估資訊:
- Currency:資料是否夠新?
- Relevance:是否跟問題高度相關?
- Authority:來源是否可信、專業?
- Accuracy:是否有可驗證數據或引用?
- Purpose:內容目的是什麼?有沒有偏見?
你也可以在提示中加上:「請根據 CRAAP 原則評估你引用的資料可信度。」
5. 定期開新對話
在同一頁面出現長對話容易出現:
- 早期錯誤被當成真相一路沿用
- 不相干內容混進答案
- 回答逐漸偏離原始目標
如果發現 AI 回答越來越不精準,
最立即見效的做法就是:開一個新對話重新問。
6. 使用「有針對性的 AI 工具」
大型通用模型什麼都會一點,但越萬能,有時也越容易亂講。
把題目交給「專門為該領域訓練」的工具,出錯機率通常會更低。
- 行銷文案:行銷型 AI / 文案工具
- 技術說明 :工程導向的 AI
- 搜尋與查證: Gemini 這類擅長檢索的模型
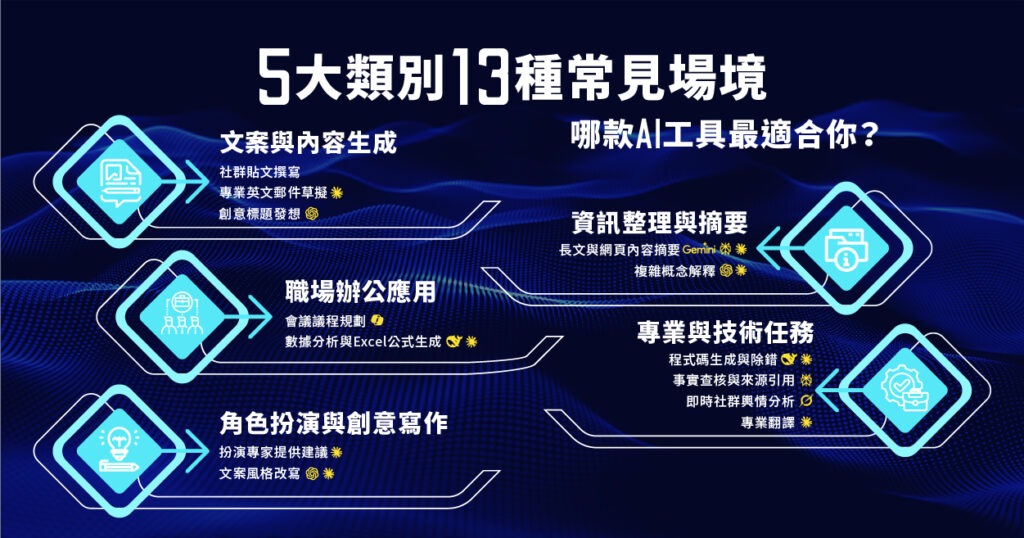
了解各種生成式 AI 工具 5 大類別 的 13 種適用場境
7. 對企業來說:導入「可管控」的環境
例如 NotebookLLM、私有化 LLM、或自家部署的模型:
- 資料不外流,安全性高
- 可以設定自己的檢測、風險控管機制
- 長期下來,成本與可控性都比完全依賴雲端公共模型更好,
這對有機密資料、法遵壓力的團隊特別重要。
8. Human-in-the-loop(HITL)永遠保留人工審查
不管內容是 AI 產出還是人寫的,
最終版本都應該經過人類審核。
這是目前企業導入 AI 專案時最常見、也最安全的做法:
- AI 負責「產出草稿、協助整理」
- 人類負責「判斷、選擇、背書」
如何避免 AI 幻覺?5 個最實用的 Prompt 技巧+範例

你不用懂模型原理,只要學會設計好提示詞(Prompt),就能大幅降低 AI 幻覺發生的機率。
以下 5 個心法+實際範例,你可以直接複製套用。
1. 提供清楚的上下文與範圍
避免使用模糊 Prompt
「蘋果的歷史。」
建議使用明確 Prompt
「請提供關於蘋果公司(Apple Inc.)從 1976 年成立到 2000 年的關鍵發展歷史,重點介紹創辦人以及這段期間推出的代表性產品。」
提示設計要點
- 明確指明「蘋果公司」而非水果
- 限制時間範圍,聚焦特定期間
- 指定內容重點(如創辦人、產品、事件)
這樣可以有效降低 AI 幻覺,讓回應更精準可靠。
2. 要求引用具體來源或依據
避免使用模糊 Prompt
「AI 會取代多少工作?」→ 模糊問題,容易生成沒有來源的資訊。
建議使用明確 Prompt
「根據高盛(Goldman Sachs)與麥肯錫(McKinsey)最近的公開報告,AI 可能對全球就業市場帶來什麼影響?請在回答中列出報告名稱、年份與關鍵數據。」
提示設計要點
- 指定可信機構
- 要求提供報告名稱、年份與數字,方便後續查證,減少 AI 隨意編造資訊
3. 設定角色與對象
避免使用模糊 Prompt
「解釋黑洞。」→ 回答可能過於簡略或過深,風格不一致。
建議使用明確 Prompt
「你是一位天體物理學家,請用大學一年級學生能理解的語言,解釋什麼是黑洞、它的形成,以及『史瓦西半徑』的概念。」
提示設計要點
- 設定角色 → 回答專業且一致
- 指定對象 → 調整難度,避免過深或過淺
4. 拆解複雜問題,要求分步驟回答
避免使用模糊 Prompt
「我應該投資股票 A 還是股票 B?」→ 容易生成武斷建議或幻覺資訊。
建議使用明確 Prompt
「請幫我分析股票 A 與股票 B 的投資風險與潛力,依以下步驟回答:
- 比較兩家公司過去一年的財務表現(營收與淨利概況)。
- 說明其所在產業的市場現況與未來成長趨勢。
- 列出各自可能面臨的三個主要風險。
- 最後總結分析,但不要直接給出『應該買哪一檔』的建議。」
提示設計要點
- 將大問題拆成小步驟
- 鎖定 AI 角色為「分析」,而非「下指令」
- 減少武斷結論與幻覺式建議
5. 鼓勵 AI 誠實說「不知道」,給它一個安全出口
避免使用模糊 Prompt
「2025 年諾貝爾物理學獎得主是誰?」→ AI 可能硬湊答案。
建議使用明確 Prompt
「請說明目前對 2025 年諾貝爾物理學獎可能得獎領域或研究方向的討論。如果尚無可靠公開資訊,請明確告訴我『目前沒有可信資料』,不要自行猜測。」
提示設計要點
- 明確要求「不要亂猜」
- 允許回答「不知道」或「資料不足」,有效降低 AI 硬湊內容與幻覺回答
3 大 AI 模型的幻覺比較:GPT、Gemini、Claude 差異
直接量化「誰比較會亂講話」其實不容易,因為會受以下因素影響:
- 使用的模型版本(GPT-3.5、GPT-4o、Gemini 1.5 Pro、Claude 3…)
- 問題類型(法律 vs. 美食 vs. 心理學)
- 任務性質(查資料、推理、創作)
- 提示詞是否清楚
不過綜合公開測試、專家評測與大量使用者回饋,
我們可以大致整理出目前主流模型的幻覺表現。
由於 GPT-5.1、Gemini 3 與 Claude Opus 4.5 剛上市,
關於它們「幻覺頻率」的第三方獨立研究和大規模用戶測試還在進行中。
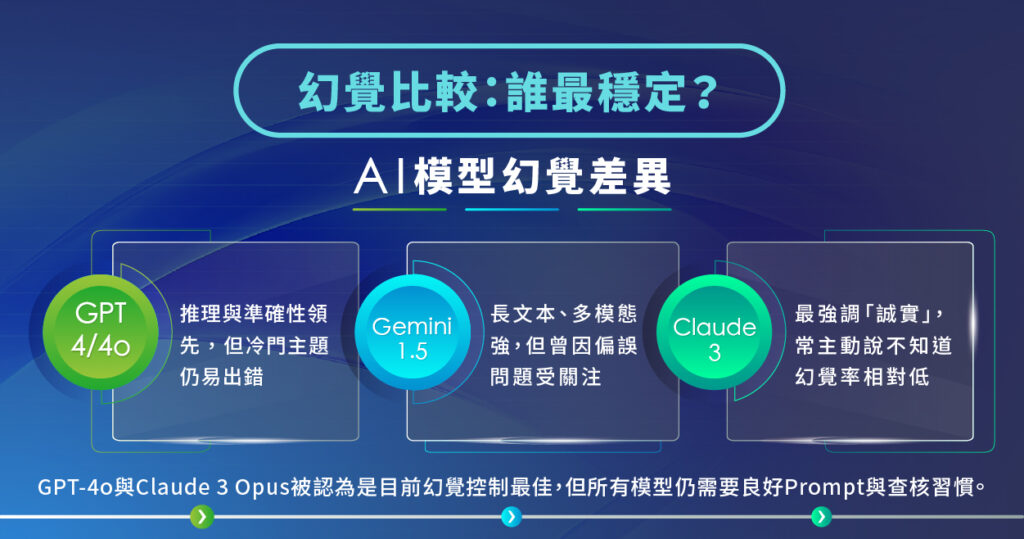
ChatGPT(OpenAI)
- GPT-4 / GPT-4o 在事實準確性與推理能力上仍被視為業界領先者之一
- 在複雜、多步驟推理任務表現穩定
- 不過在:
- 非常專業的利基領域
- 最新消息(超過其知識截止日期)
- 資料很少的冷門主題
仍然會出現看似自信,實則錯誤的回答
Gemini(Google)
- Gemini 1.5 Pro 非常擅長處理長文本與多模態(文字+圖片+影片)內容
- 在一些基準測試中,事實準確度與 GPT-4 相近,有時略優、有時略弱
- 曾因歷史圖像生成等議題出現系統性偏誤,引發熱議——這也可以視為某種形式的「幻覺」
Claude(Anthropic)
- Claude 3 系列(特別是 Opus) 強調安全性與「誠實性」
- 不知道的時候,更傾向說「我不確定」「沒有足夠資訊」
- 在很多實測中,被認為幻覺率相對較低,尤其是當你明確要求「不要亂編」時
小結:
- GPT-4o 與 Claude 3 Opus 通常被認為是目前「幻覺控制最佳」的一線模型,
但沒有任何一個模型能完全避免幻覺 - 越新的、越大的模型,在多數情境下幻覺率較低,但依舊需要使用者良好的提示詞與查核習慣
不同模型各有強項,若能「用對場景」,不僅效率更高,也能有效降低 AI 幻覺。
點擊以下圖片看完整內文:生成式 AI 工具挑選指南:5 大類別、13 種常見應用場境一次看
AI 幻覺常見問題 Q&A
Q1.什麼是 AI 幻覺?
AI 幻覺(AI Hallucination Definition)指的是大型語言模型(如 ChatGPT、Gemini、Claude)產生看似合理但實際錯誤或虛構的內容。這通常源於模型以機率方式生成答案,而非真正理解或查證事實。
Q2. 為什麼 AI 模型會產生幻覺?
AI 模型會產生幻覺常見原因包括:
- 以機率預測詞語,而非驗證真實性
- 訓練資料本身包含錯誤或矛盾資訊
- 冷門題目或資料不足造成 AI「腦補」
- 模糊提示詞讓模型自行推測
- 過度泛化或誤套訓練模式
Q3. AI 幻覺會帶來什麼風險?
依產業不同可能造成不同程度的問題,包括:
- 醫療:錯誤症狀解讀或虛構研究
- 法律:虛構案例、誤引用條文
- 金融與投資:捏造數據或過度簡化分析
- 教育與寫作:錯誤知識被大量引用
因此,AI 幻覺具有「資訊危害性」,在專業領域尤其需要警惕。
Q4. AI 幻覺可以被完全修正嗎?
目前無法完全根除幻覺,短期內 AI 仍會持續有幻覺。
然而可以透過以下方法大幅降低:
- 使用 RAG(檢索增強生成)接資料庫
- 限制題目範圍、提供明確上下文
- 要求來源驗證
- 使用防幻覺提示詞
- 讓 AI 進入逐步推理模式(structured reasoning)
Q5. ChatGPT、Gemini、Claude 的幻覺率誰最低?
幻覺率會依模型版本、領域及問題複雜度而變動,目前沒有任何模型能做到 0 幻覺。
綜合目前研究趨勢:
- Claude 3(Opus):在誠實性與「不知道就說不知道」的表現較突出,被視為幻覺率較低
- GPT-4o:在推理與資料一致性上非常穩定
- Gemini 1.5 Pro:在長內容、多模態資料上強,但在特定領域曾出現偏誤
Q6. 如何預防 AI 幻覺?
可採取以下策略:
- 問清楚:給上下文、限制範圍
- 要求來源:請 AI 引用文獻、段落、網址
- 分步推理(Chain of Thought)
- 交叉查證:問多個模型(ChatGPT + Gemini + Claude)
- 允許 AI 說不知道:降低編造機率
- 使用 RAG 或上傳資料:讓模型有可依據的事實庫
Q7. RAG 能降低 AI 幻覺嗎?
RAG(Retrieval-Augmented Generation, 檢索增強生成)透過先「搜尋真實資料」再生成回答,因此能大幅提高正確率,是目前企業最常採用的反幻覺技術之一。但:
- 資料庫品質仍決定答案品質
- 若檢索不到資料,模型仍可能開始「補戲」
總結:AI 幻覺無法避免,但可以大幅管控
無論 AI 技術如何進步,目前最保險的商業應用模式仍是 Human-in-the-loop (人在迴圈中)。
這意味著,AI 產出的內容不應直接發布,而必須經過人類的最終審核。
實務上,建議採取「金字塔證據等級」法:
- 底層: 由 AI 快速生成草稿與架構。
- 中層: 利用 NotebookLLM 進行資料比對。
- 頂層: 由人類專家進行最終事實查核 (Fact Check) 與潤飾。
如果你是行銷人、內容創作者、PM、顧問,
在開始追求「用 AI 提升效率」之前,
先學會「如何跟 AI 安全合作」與「如何降低 AI 幻覺」,
才是真正保護自己與專業信用的第一步。
Leadion AI 的專業顧問團隊,能協助你快速釐清「哪些流程該交給 AI、哪些保留給人」,
在效率、成本與風險之間找到最理想的協作策略,避免盲目試錯、浪費人力。
填寫【線上諮詢表單】,我們的 AI 顧問將在 1 個工作天內主動與你聯繫!
協助你把 AI 真正導入工作流程、創造立即可見的價值。
想取得 AI 工具的最新資訊?馬上訂閱 Leadion AI 電子報,學會如何在工作與生活中應用,
獲得最新的 AI 實戰技巧、產業趨勢與工具應用案例,
讓 AI 成為你的競爭優勢!





